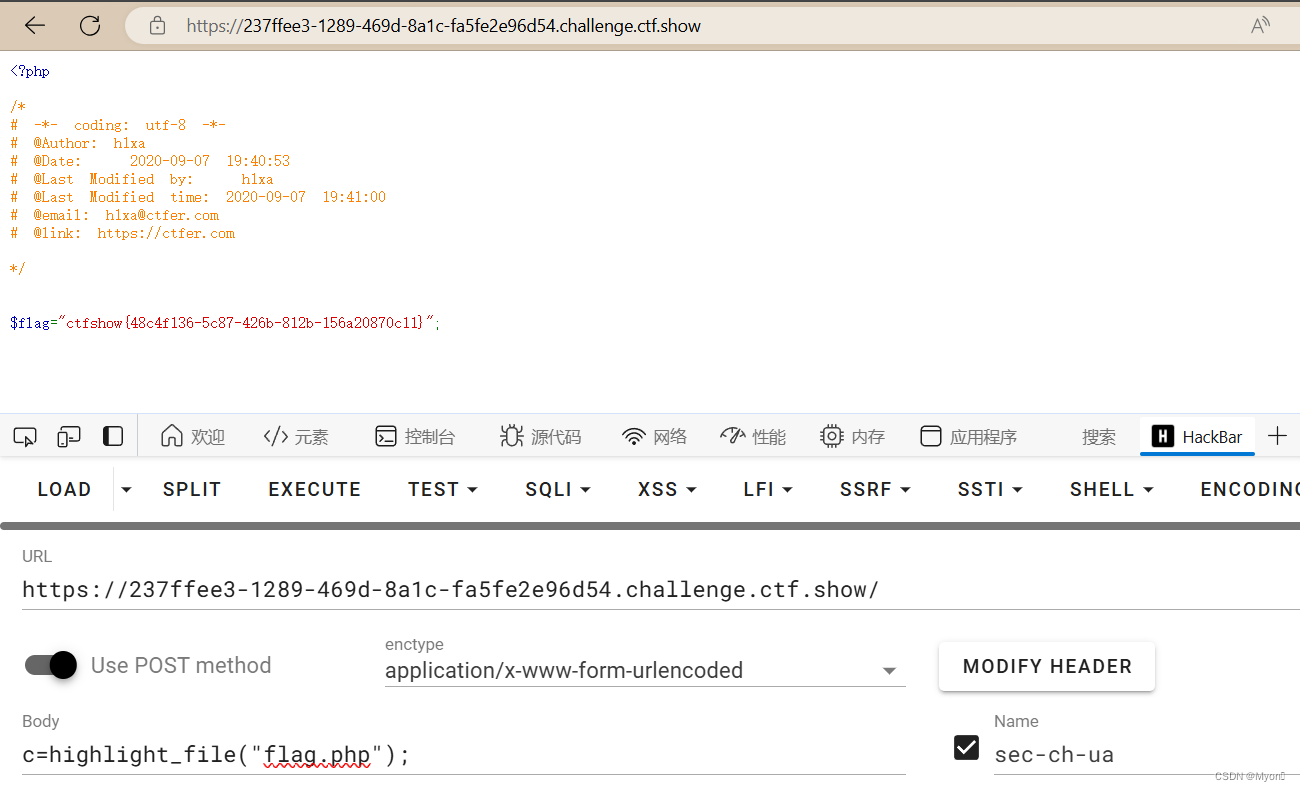
一:访问各个节点中的数据
(1)访问链表中的各个节点的有效数据,这个访问必须注意不能使用p、p1、p2,而只能使用phead
(2)只能用头指针不能用各个节点自己的指针。因为在实际当中我们保存链表的时候是不会保存各个节点的指针的,只能通过头指针来访问链表节点
(3)前一个节点的pNEXT指针能帮助我们找到下一个节点
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
//构建一个链表的节点
struct node
{
int datas; //有效数据
struct node *pNEXT; //指向下一个节点的指针
};
int main(void)
{
//定义头指针
struct node *phead = NULL;
//创建一个链表节点
struct node *p = (struct node *)malloc(sizeof(struct node));
if(NULL == p) //检查申请结果是否正确
{
printf("malloc error!\n");
return -1;
}
//memset(p,0,sizeof(struct node));
bzero(p,sizeof(struct node)); //清理申请到的堆内存
//填充节点
p->datas = 1; //填充数据区
p->pNEXT = NULL; //将来要执行下一个节点的首地址
phead = p; //将本节点和前面的头指针关联起来
//创建一个链表节点并和上一个节点关联起来
struct node *p1 = (struct node *)malloc(sizeof(struct node));
if(NULL == p1) //检查申请结果是否正确
{
printf("malloc error!\n");
return -1;
}
//memset(p,0,sizeof(struct node));
bzero(p1,sizeof(struct node)); //清理申请到的堆内存
//填充节点
p1->datas = 1; //填充数据区
p1->pNEXT = NULL; //将来要执行下一个节点的首地址
p-pNEXT>= p1; //将本节点和前面的节点关联起来
//再创建一个链表节点并和上一个节点关联起来
struct node *p2 = (struct node *)malloc(sizeof(struct node));
if(NULL == p2) //检查申请结果是否正确
{
printf("malloc error!\n");
return -1;
}
//memset(p2,0,sizeof(struct node));
bzero(p2,sizeof(struct node)); //清理申请到的堆内存
//填充节点
p2->datas = 1; //填充数据区
p2->pNEXT = NULL; //将来要执行下一个节点的首地址
p1-pNEXT>= p2; //将本节点和前面的节点关联起来
//访问链表节点的第一个节点的有效数据
printf("phead->p->datas = %d\n",phead->datas);
printf("p->datas = %d\n",p->datas);
//访问链表节点的第二个有效数据
printf("phead->pNEXT->datas =%d\n",phead->pNEXT->datas);
printf("p1->datas = %d\n",p1->datas);
//访问链表节点的第三个有效数据
printf("phead->pNEXT->datas = %d\n",phead->pNEXT->pNEXT->datas);
printf("p2->datas = %d\n",p2->datas);
return 0;
}二:将创建的节点封装成一个函数
(1)封装时的关键就是函数的接口(函数参数和返回值)的设计
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
//构建一个链表的节点
struct node
{
int datas; //有效数据
struct node *pNEXT; //指向下一个节点的指针
};
/****************************************
函数名:create
作用:创建一个链表节点
返回值:p 指针,指针指向本函数创建的一个节点的首地址
参数:
****************************************/
struct node *create(int a)
{
struct node *p = (struct node *)malloc(sizeof(struct node));
if(NULL == p)
{
printf("malloc error!\n");
return NULL;
}
memset(p,0,sizeof(struct node));
//bzero(p,sizeof(struct node));
p->datas = a;
p->pNEXT = NULL;
return p;
int main(void)
{
//定义头指针
struct node *phead = NULL;
//调用函数实现创建链表节点并将数据放到有效数据区
phead = create(100); //调用一次函数,创建一个链表节点返回节点首地址给头指针
phead->pNEXT = create(200); //再次创建一个链表节点返回节点首地址给上一个节点的指针
phead->pNEXT->pNEXT = create(300); //同上
printf("phead->p->datas = %d\n",phead->datas);
//printf("p->datas = %d\n",p->datas); //使用功能函数创建链表节点就不能再使用
//节点指针访问有效数据区,只能通过头
//指针
printf("phead->pNEXT->datas =%d\n",phead->pNEXT->datas);
//printf("p1->datas = %d\n",p1->datas);
printf("phead->pNEXT->datas = %d\n",phead->pNEXT->pNEXT->datas);
//printf("p2->datas = %d\n",p2->datas);
return 0;
}
}运行结果:
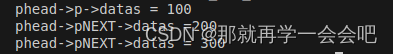
三:从链表头部插入新节点
(1)思路:第一步:新节点的next指向原来的第一个节点
第二步:头指针的next指向新节点
第三步:头节点的计数要加一
(2)代码示例:
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
struct node
{
int datas;
struct node *pNEXT;
};
struct node *create(int a)
{
struct node *p = (struct node *)malloc(sizeof(struct node));
if(NULL == p)
{
printf("malloc error!\n");
return NULL;
}
memset(p,0,sizeof(struct node));
//bzero(p,sizeof(struct node));
p->datas = a;
p->pNEXT = NULL;
return p;
}
void insert_tail(struct node *phead,struct node *new)
{
struct node *p = phead;
int cat = 0;
while(NULL != p->pNEXT)
{
p = p->pNEXT;
cat++;
}
p->pNEXT = new;
phead->datas = cat +1;
}
void insert_head(struct node *head,struct node *new)
{
new->pNEXT = head->pNEXT; //新节点的next指向之前的第一个节点
head->pNEXT = new; //头节点的next指向新节点地址
head->datas += 1; //头节点的计数加一
}
int main(void)
{
struct node *phead = create(0);
insert_head(phead,create(1));
insert_head(phead,create(2));
insert_head(phead,create(3));
/*
phead = create(100);
phead->pNEXT = create(200);
phead->pNEXT->pNEXT = create(300);
*/
printf("phead->p->datas = %d\n",phead->datas);
//printf("p->datas = %d\n",p->datas);
printf("phead->pNEXT->datas =%d\n",phead->pNEXT->datas);
//printf("p1->datas = %d\n",p1->datas);
printf("phead->pNEXT->datas = %d\n",phead->pNEXT->pNEXT->datas);
//printf("p2->datas = %d\n",p2->datas);
printf("phead->pNEXT->datas = %d\n",phead->pNEXT->pNEXT->pNEXT->datas);
//printf("p2->datas = %d\n",p2->datas);
return 0;
}运行结果:

四:从链表尾部插入新节点
(1)思路:从头指针往后开始遍历指针指向的地址判断是不是NILL,直到最后一个节点,因为最后一个节点的是指向NULL的,所以遍历结束,然后将最后一个节点的指针指向新创建的节点
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
//构建一个链表的节点
struct node
{
int datas;
struct node *pNEXT;
};
//创建一个链表节点
struct node *create(int a)
{
struct node *p = (struct node *)malloc(sizeof(struct node));
if(NULL == p)
{
printf("malloc error!\n");
return NULL;
}
memset(p,0,sizeof(struct node));
//bzero(p,sizeof(struct node));
p->datas = a;
p->pNEXT = NULL;
return p;
}
//从尾部插入节点
void insert_tail(struct node *phead,struct node *new)
{
struct node *p = phead; //定义临时指针变量
//循环遍历指针
while(NULL != p->pNEXT)
{
p = p->pNEXT;
}
p->pNEXT = new; //节点尾部指针指向新节点
}
int main(void)
{
struct node *phead = create(100); //由于实现尾部插入判断是否是最后一个节点
//所以如果将头指针指向NULL那么程序就出错了
//这里就先创建一个节点让头指针指向它
insert_tail(phead,create(200)); //再从单链接尾部插入节点
insert_tail(phead,create(300)); //同上
/*
phead = create(100);
phead->pNEXT = create(200);
phead->pNEXT->pNEXT = create(300);
*/
printf("phead->p->datas = %d\n",phead->datas);
//printf("p->datas = %d\n",p->datas);
printf("phead->pNEXT->datas =%d\n",phead->pNEXT->datas);
//printf("p1->datas = %d\n",p1->datas);
printf("phead->pNEXT->datas = %d\n",phead->pNEXT->pNEXT->datas);
//printf("p2->datas = %d\n",p2->datas);
return 0;
}(2)问题:因为我们在inserttail中直接默认了头指针指向的有一个节点,因此如果程序中直接
定义了头指针后就直接insert tail就会报段错误。我们不得不在定义头指针之后先create_node
创建一个新节点给头指针初始化,否则不能避免这个错误;但是这样解决让程序看起来逻辑有点
不太顺,因为看起来第一个节点和后面的节点的创建、添加方式有点不同。
(3)链表还有另一种用法,就是把头指针指向的第一个节点作为头节点使用。头节点的特点是它紧跟在头指针后面;它的数据区是空的(有时候不是空的,用来存储链表节点个数);指针部分指向下一个节点(第一个链表节点)
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
//构建一个链表的节点
struct node
{
int datas;
struct node *pNEXT;
};
//创建一个链表节点
struct node *create(int a)
{
struct node *p = (struct node *)malloc(sizeof(struct node));
if(NULL == p)
{
printf("malloc error!\n");
return NULL;
}
memset(p,0,sizeof(struct node));
//bzero(p,sizeof(struct node));
p->datas = a;
p->pNEXT = NULL;
return p;
}
//从尾部插入节点
void insert_tail(struct node *phead,struct node *new)
{
struct node *p = phead; //定义临时指针变量
int cat = 0; //创建一个计数器变量
//循环遍历指针
while(NULL != p->pNEXT)
{
p = p->pNEXT;
cat++; //每循环一次加一
}
p->pNEXT = new; //节点尾部指针指向新节点
phead->datas = cat +1;
}
int main(void)
{
struct node *phead = create(0); //由于实现尾部插入判断是否是最后一个节点
//所以如果将头指针指向NULL那么程序就出错了
//这里就先创建一个头节点让头指针指向它
insert_tail(phead,create(1));
insert_tail(phead,create(2));
insert_tail(phead,create(3));
/*
phead = create(100);
phead->pNEXT = create(200);
phead->pNEXT->pNEXT = create(300);
*/
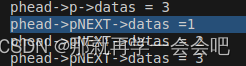
printf("phead->p->datas = %d\n",phead->datas); //节点数
printf("phead->pNEXT->datas =%d\n",phead->pNEXT->datas); //第一个节点数据区数据
printf("phead->pNEXT->datas = %d\n",phead->pNEXT->pNEXT->datas); //第二个
printf("phead->pNEXT->datas = %d\n",phead->pNEXT->pNEXT->pNEXT->datas); //三
return 0;
}运行 结果:链表节点数 3 第一个节点数据区为1 第二个为2 第三个为3
(4)这样看来,头节点确实和其他节点不同。我们在创建一个链表时添加节点的方法也不同。头
节点在创建头指针时一并创建并且和头指针关联起来;后面的真正的存储数据的节点用节点添加
的函数来完成,譬如insert tail。
(5)链表有没有头节点是不同的。体现在链表的插入节点、删除节点、遍历节点、解析链表的各
个算法函数都不同。所以如果一个链表设计的时候就有头节点那么后面的所有算法都应该这样来
处理:如果设计时就没有头节点,那么后面的所有算法都应该按照没有头节点来做。实际编程中
两种链表都有人用,所以程序员在看别人写的代码时一定要注意看它有没有头节点
注意:注意在写代码过程中的箭头符号,和说话过程中的指针指向。这是两码事,容易搞混箭头符号实质是用指针来访问结构体,所以箭头的实质是访问结构体中的成员。清楚的来说程序中的箭头和链表的连接没有任何的关系;链表中的节点通过指针指向来连接,编程中表现为赋值语句(用=来连接),实质是把最后一个节点的首地址,赋值给前一个节点中的pnext元素作为值
链表可以从头部插入,也可以尾部插入,也可以两头插入。对链表来说几乎没有差别,但是有时候对业务逻辑有差别